
Microservices or monolit, synchronous or asynchronous communication, who is responsible, does it make sense, is it intuitive, should we use Kafka? These are questions of the last decade, never-ending fights during battles..

As a pragmatic man, I am not going to tell you which technology is the ultimate one. I’ll simply explain when to choose which approach and the rest is up to you.
REST API
Representational state transfer – this is the obvious and easiest option to choose when thinking about your service driving the flow. Why? You immediately know that something went wrong (error result, server not available etc.) and can react to that in a straightforward way.
There are many libraries out there that help you build a client and also a server in matter of minutes with plenty of security protocols at your disposal. You can even include service discovery, client pooling, load balancing etc.
So far so good, right? Now imagine that your operations are not as fast as you want. This kind of breaks your design, because you either must include explicit parallel programming (if possible considering the flow) or you might meet technical limits which cannot be solved at all (you’re out of connections).
I know I know, the above mentioned is an issue just for developers. Customer doesn’t care, product owner doesn’t care, architect doesn’t care. So let’s try this. What if your service is responsible for notifying other services? Two problems:
- in case of delivery failure, you must keep the state of delivery somewhere and that somewhere is your service
- you must know the exact list of other services you need to notify, which creates tight coupling (both systems know about each other)
Messaging
The answer to situations mentioned above is messaging. But why is that?
Here’s a couple of reasons:
- calls are not blocking
- once a message is en-queued, your job is done, if other service is down, the message will wait for it in the queue
- you don’t even have to know how many consumers react to your message or whether they will react at all
- this is an opportunity for an event based plug-in system
- no service discovery service is necessary
- you get load balancing out of the box (only when worker is done, it gets another message)
Once again, so far so good. Now the hard choice – which messaging system shall you use?
JMS
Once upon a time, there was this idea to have asynchronous systems. And very good idea it was.

JMS is a standard, meaning it only dictates the behavior and interfaces. Implementation is completely up to individual implementations. Let’s mention some of them
- Apache ActiveMQ – now known also as Apache ActiveMQ Classic
- MQSeries – known also as Websphere MQ and now IBM MQ
- HornetQ – known also as JBoss Messaging and now developed under Apache as ActiveMQ Artemis
- RabbitMQ – this one I will mention later one more time
The possibilities of JMS are now quite limited. There’s a concept of producer (who sends the message) and consumer (who receives the message). You can either send the message to a Queue or a Topic. If anybody reads the message from the Queue, others will not receive it (if you pop a message, it’s gone). If you need to deliver the message to everybody, you will send the message to a Topic. Everybody subscribed will receive it.
It seems like a very good start. But then real life happens and you need to deliver to exactly 2 or 3 systems, have the message delivered to everybody even if they are not subscribed at the moment of dispatching the message (yes, topic delivers to everybody subscribed at that time). Sometimes you need to redeliver everything once again. This can always be solved by introducing dedicates persistent queues. However, is it the correct way? It’s not, because once again, we have tight coupling – new system means new queue, change of code/config on consumer and also producer side.
Many features were missing and added as implementation specific configuration or headers. Imagine a simple scenario, where you need to postpone message delivery. It is not available in JMS specs. Therefore, each implementation requires different header and different connection string setup. Oh yes, why would you need delayed delivery? In case consumer fails to process a message, it can simply return it to a retry queue and do it once again in 15 seconds (when some other systems might be back online again).
RabbitMQ

RabbitMQ provides JMS, but offers also its own extension which solves most of the JMS problems.
First of all, let’s forget there are Queues and Topics. There are Exchanges and Queues. What’s the difference? Producer sends a message to an Exchange with some meta data describing it (called routing key). It doesn’t know who is going to process the message and not even how many other systems if any at all. Consumers create and manage queues by themselves, they also configure which messages from which exchange under which conditions end up in the queue – it is called binding.
Better one good example than thousand words – Core System emits notification about new Order and sends it to its exchange named Orders with routing key order.new.123:
- Core System emits notification about new Order and sends it to its exchange named Orders with routing key order.new.123
- various other systems are in place which have their queues bound to the exchange
- Customer notification system has it’s queue CustomerNotifications bound to Orders.
- There are in fact two instances of notification system and since they share the queue, they are load-balanced using round robin
- Warehouse employees system has it’s queue Packaging bound to Orders with routing limited to order.new
- this system sadly does not support load balancing there is only one instance
- however, if it is down when order is creates, messages will be processed once it is up again
This is the true power of RabbitMQ – event based communication where you plugin other systems.
Kafka
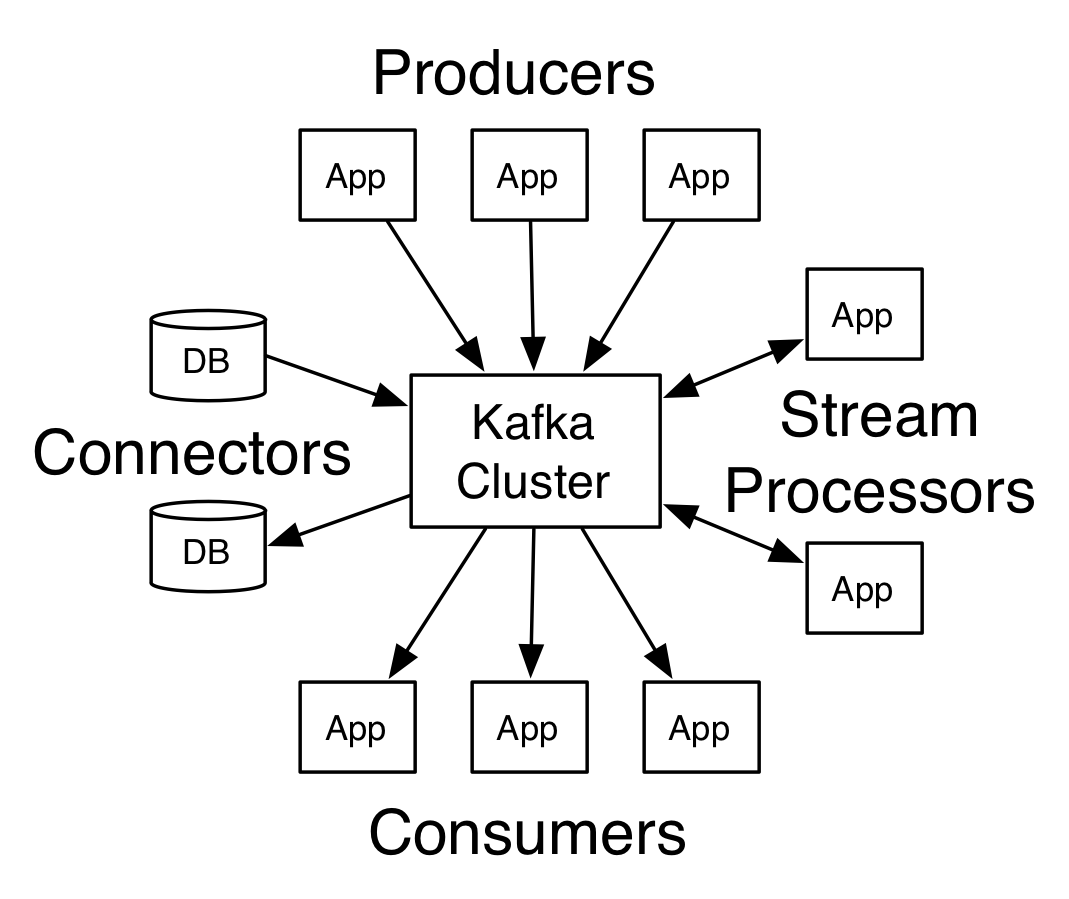
Apache Kafka solves things differently. It’s principle addresses the same problems JMS has, but not using exchanges and queue, but rather topics, partitions and consumer groups. Reason being is the purpose of Kafka – high performance streaming platform.
What is a consumer group? If a set of consumers belongs to the same consumer group, only one of them processes the message sent to the topic. So if there are 3 consumer groups for given topic, the message will be processed exactly 3 times (even if there are more systems, but belonging to the same consumer group). When compared to RabbitMQ, it’s the same as if topic was exchange and there were 3 queues bound to that exchange.
In case you realize your system processed the messages incorrectly, you can replay these messages. It depends on retention policy (e.g. keep messages for 7 days). Additionally, consumer can read the messages backwards and forwards like it was a list, not a read-me-once queue. Might not look like a great feature, but imagine how many race condition scenarios can be solved by this when you know Kafka also guarantees message ordering.
The best out of the box feature is replication. Apache ActiveMQ is quite shitty in this area, because it offers you only fallback servers – in case you loose connectivity, you can use another server – but was it you who lost connectivity, was it only partial loss, what happened to messages that were dispatched to old instance? Apache Kafka offers you the possibility to replicate messages among servers and consider the message delivered only if it was replicated to at least N nodes. You can choose whether you want to have high performance (1 node out of 10 confirmed the message) or high reliability (10 out of 10 confirmed the message). Usually, you would go for something in between
However, Kafka is not the ultimate technology for messaging – first of all, the configuration is server side. You can not simply plug-in new system without creating new consumer group. You can not even address one particular consumer, because once again, there are no queues and possobility to have dynamic consumer groups. Workaround is to send the message to all consumers and let them decide whether they were the addressee, but it is against the principle that the middleware should help services process only what is necessary.
Simply said, Kafka is reliable, fast and scalable, but it’s just not purely messaging system and it’s not meant to be.
Conclusion
So, to make things easy- JMS is dead, REST is fine for simple scenarios, RabbitMQ is the thing you want and Kafka can be used too. It’s also possible to combine these methods – offer REST API to create the record, but asynchronously process it later and deliver updates via messaging.
In any case, use what you have available and supported by your IT unless you don’t need that little extra one of the methods offers.